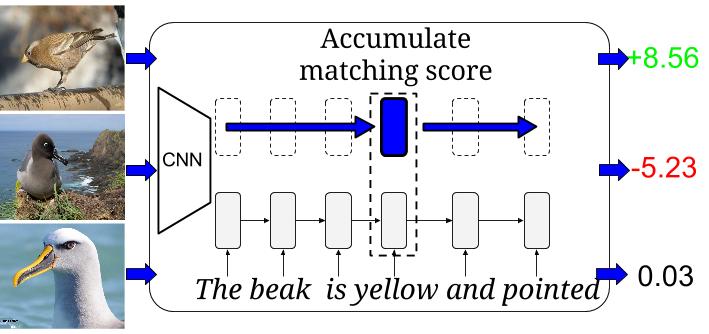
Scott Reed, Zeynep Akata, Xinchen Yan, Lajanugen Logeswaran, Bernt Schiele, Honglak Lee
This is the code for our ICML 2016 paper on text-to-image synthesis using conditional GANs. You can use it to train and sample from text-to-image models.
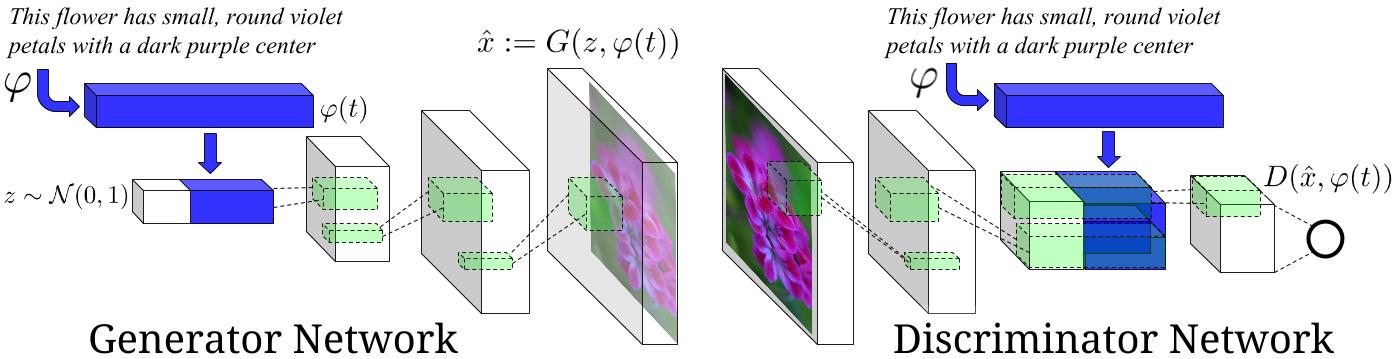 For setup and usage please visit: https://github.com/reedscot/icml2016
For setup and usage please visit: https://github.com/reedscot/icml2016
You can also interest in Learning Deep Representations of Fine-grained Visual Descriptions