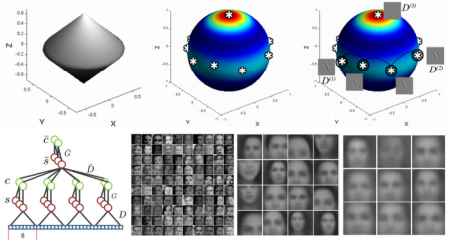
We introduce an unsupervised feature learning algorithm that is trained explicitly with k-means for simple cells and a form of agglomerative clustering for complex cells. When trained on a large dataset of YouTube frames, the algorithm automatically discovers semantic concepts, such as faces.
Etiket: Andrej Karpathy
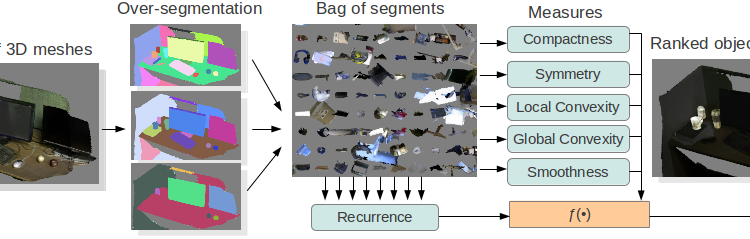
Makale: Object Discovery in 3D scenes via Shape Analysis
We present a method for discovering object models from 3D meshes of indoor environments. Our algorithm first decomposes the scene into a set of candidate mesh segments and then ranks each segment according to its “objectness” — a quality that distinguishes objects from clutter. To do so, we propose five intrinsic shape measures: compactness, symmetry, smoothness, and local and global convexity. We additionally propose a recurrence measure, codifying the intuition that frequently occurring geometries are more likely to correspond to complete objects. We evaluate our method in both supervised and unsupervised regimes on a dataset of 58 indoor scenes collected using an Open Source implementation of Kinect Fusion. We show that our approach can reliably and efficiently distinguish objects from clutter, with Average Precision score of .92. We make our dataset available to the public.
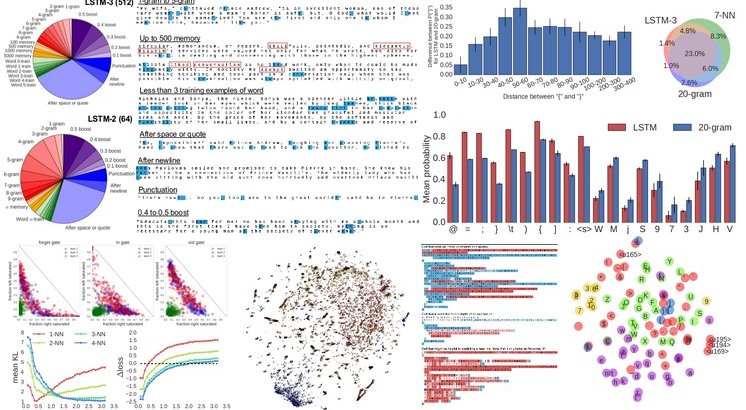
Makale: Visualizing and Understanding Recurrent Networks
Recurrent Neural Networks (RNNs), and specifically a variant with Long Short-Term Memory (LSTM), are enjoying renewed interest as a result of successful applications in a wide range of machine learning problems that involve sequential data. However, while LSTMs provide exceptional results in practice, the source of their performance and their limitations remain rather poorly understood. Using character-level language models as an interpretable testbed, we aim to bridge this gap by providing a comprehensive analysis of their representations, predictions and error types. In particular, our experiments reveal the existence of interpretable cells that keep track of long-range dependencies such as line lengths, quotes and brackets. Moreover, an extensive analysis with finite horizon n-gram models suggest that these dependencies are actively discovered and utilized by the networks. Finally, we provide detailed error analysis that suggests areas for further study.
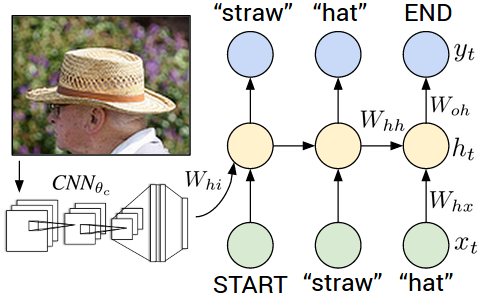
Makale: Deep Visual-Semantic Alignments for Generating Image Descriptions
We present a model that generates free-form natural language descriptions of full images and their regions. For generating sentences about a given image region we describe a Multimodal Recurrent Neural Network architecture. For inferring the latent alignments between segments of sentences and regions of images we describe a model based on a novel combination of Convolutional Neural Networks over image regions, bidirectional Recurrent Neural Networks over sentences, and a structured objective that aligns the two modalities through a multimodal embedding. This work was also featured in a New York Times article.