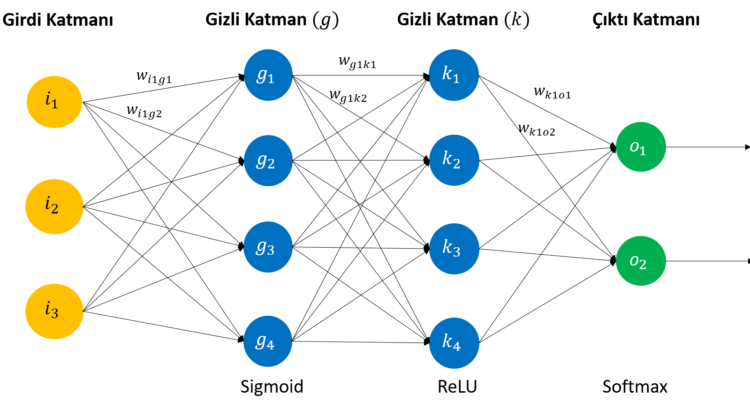
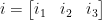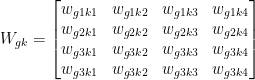Kasım 13, 2018
 SONY araştırmacıları ImageNet/ResNet-50 eğitimini 2100 tane NVIDIA Tesla V100 Tensor Core GPU’ları ile sadece 224 saniyede (3 dakika 44 saniye) %75 doğruluk tamamladıklarını duyurdu. Bu başarım, yayınlanmış en hızlı ResNet-50 eğitim süresi anlamına geliyor.
SONY araştırmacıları ImageNet/ResNet-50 eğitimini 2100 tane NVIDIA Tesla V100 Tensor Core GPU’ları ile sadece 224 saniyede (3 dakika 44 saniye) %75 doğruluk tamamladıklarını duyurdu. Bu başarım, yayınlanmış en hızlı ResNet-50 eğitim süresi anlamına geliyor.
Takım, aynı zamanda 1088 adet NVIDIA Tesla V100 Tensor Core GPU’ları ile %90’ın üzerinde GPU ölçekleme verimi elde etmeyi başardı.
ImageNet/ResNet-50 eğitiminde GPU ölçekleme verimi
|
İşlemci |
Ara Bağlantı |
GPU ölçekleme verimi |
| Goyal ve diğ. [1] |
Tesla P100 x256 |
50Gbit Ethernet |
∼90% |
| Akiba ve diğ. [5] |
Tesla P100 x1024 |
Infiniband FDR |
80% |
| Jia ve diğ. [6] |
Tesla P40 x2048 |
100Gbit Ethernet |
87.90% |
| Bu çalışma |
Tesla V100 x1088 |
Infiniband EDR x2 |
91.62% |
ImageNet/ResNet-50 ile eğitim süresi ve en iyi doğrulama doğruluğu SONY takımı makalesinde “Derin öğrenmede artış için veri seti boyutu ve derin sinir ağı (DNN) modeliyle birlikte, modeli eğitmek için gereken zaman da artıyor.” yazdı.
|
Paket büyüklüğü |
İşlemci |
DL Kütüphanesi |
Süre |
Doğruluk |
| He ve diğ. |
256 |
Tesla P100 x8 |
Caffe |
29 saat |
75.30% |
| Goyal ve diğ. |
8K |
Tesla P100 x256 |
Caffe2 |
1 saat |
76.30% |
| Smith ve diğ. |
8K→16K |
full TPU Pod |
TensorFlow |
30 dk |
76.10% |
| Akiba ve diğ. |
32K |
Tesla P100 x1024 |
Chainer |
15 dk |
74.90% |
| Jia ve diğ. |
64K |
Tesla P40 x2048 |
TensorFlow |
6.6 dk |
75.80% |
| Bu çalışma |
34K→68K |
Tesla V100 x2176 |
NNL |
224 sn |
75.03% |
Takım bu rekoru kırmak için, araştırmacılar iki öncelikli konu olan: geniş mini-paket eğitimi kararsızlığı ve takım içi iletişim uyumluluğu ile büyük ölçekli dağıtımlı eğitimine önem verdiklerini ifade etti.
Araştırmacılar, “Biz geniş mini-paket kararsızlığını göstermek için bir paket boyu kontrol tekniğini benimsedik.” dedi. “Aynı zamanda, GPU’lar arasında verimli bir gradient değişimi için 2D-Torus şeması geliştirdik.”
2D-Torus, verimli bir haberleşme topolojisi gibi hizmet veriyor ve bu da iletişimde takıma uyum sağlama süresini azaltıyor.
Yazılım: Takım “Derin Sinir Ağı eğitim kütüphanesi (DNN) olarak Yapay Sinir Ağı Kütüphaneleri (NNL) ve bunların CUDA eklentilerini kullandık.” dedi. “NNL 1.0.0 CUDA 9.0 verisonları tabanlı geliştirme kolları ile GPU’larda DNN eğitimi için de cuDNN 7.3.1’i kullandık.”
Takım, makalelerinde “Haberleşme kütüphanesi olarak NCCL versiyon 2.3.5 ve OpenMPI versiyon 2.1.3’ü kullandık. 2D-Torus all-reduce ise NCCL2 ile uygulandı. Yukarıdaki yazılım da bir Singularity konteyner içinde paketlendi. Dağılmış DNN eğitimini koşturmak için Singularity versiyon 2.5.2’yi kullandık.” yazdı.
Bu çalışma geliştirme kütüphanesini güçlendirdi “Çekirdek Kütüphanesi: Sinir Ağı Kütüphaneleri Sony tarafından geliştirildi ve AI Bridging Cloud Infrastructure (ABCI) süper bilgisayarı, birinci sınıf hesaplama altyapısı Japan’s National Institute of Advanced Industrial Science and Technology (AIST) tarafından kuruldu ve işletildi. Bu sistem 4300 adet NVIDIA Volta Tensor Core GPU’ları tarafından çalıştırılıyor.
Kaynak: Nvidia Developer News Center
 Günümüzde hava durumu ajansları ve rüzgar çiftlikleri, hava alanları, lojistik merkezleri, denizcilik operasyonları ve diğer birçok kuruluş, çoklu düğümlerde karmaşık bilgi işlem kümeleri üzerinde özelleştirilmiş hava durumu tahminleri yürütmektedir.
Günümüzde hava durumu ajansları ve rüzgar çiftlikleri, hava alanları, lojistik merkezleri, denizcilik operasyonları ve diğer birçok kuruluş, çoklu düğümlerde karmaşık bilgi işlem kümeleri üzerinde özelleştirilmiş hava durumu tahminleri yürütmektedir.