Otonom araçların görüntü tabanlı olarak ilerlemesi tekniği üzerine Princeton Universitesi Vision Grubu’nun Google, Intel ve NVIDIA’nın desteğiyle yürüttüğü çalışmanın makalesi ve kodlamasının duyurusu yapıldı. Özellikle otonom araçların şerit ve araç takibini nasıl yapacağı üzerine mevcut yöntemlerle Convolution Neural Network yönteminin kıyaslamasını aşağıdaki videodadan izleyebilirsiniz.
Abstract:
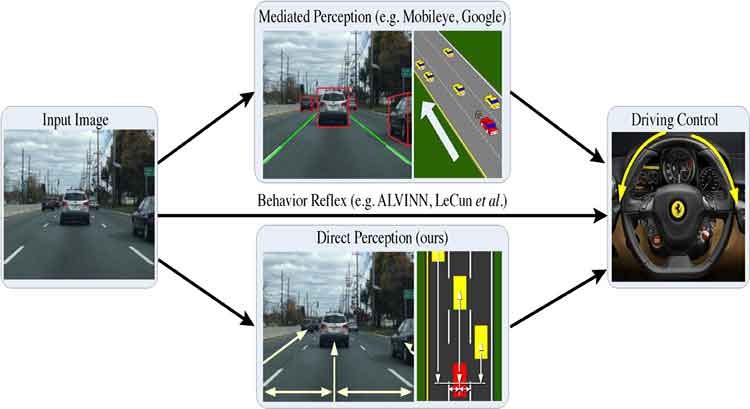
Today, there are two major paradigms for vision-based autonomous driving systems: mediated perception approaches that parse an entire scene to make a driving decision, and behavior reflex approaches that directly map an input image to a driving action by a regressor. In this paper, we propose a third paradigm: a direct perception based approach to estimate the affordance for driving. We propose to map an input image to a small number of key perception indicators that directly relate to the affordance of a road/traffic state for driving. Our representation provides a set of compact yet complete descriptions of the scene to enable a simple controller to drive autonomously. Falling in between the two extremes of mediated perception and behavior reflex, we argue that our direct perception representation provides the right level of abstraction. To demonstrate this, we train a deep Convolutional Neural Network (CNN) using 12 hours of human driving in a video game and show that our model can work well to drive a car in a very diverse set of virtual environments. Finally, we also train another CNN for car distance estimation on the KITTI dataset, results show that the direct perception approach can generalize well to real driving images.