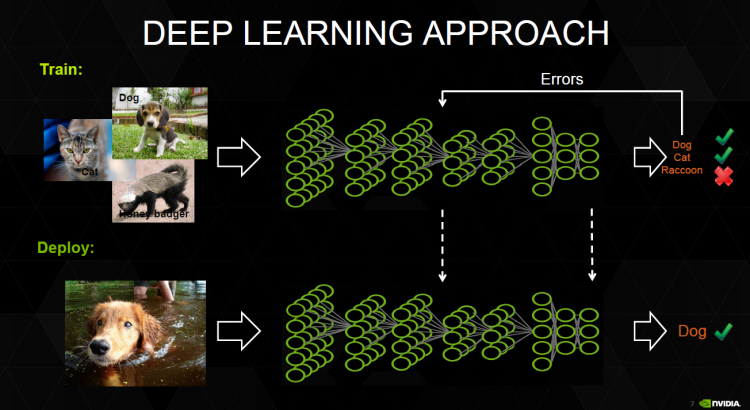
NVIDIA’nın düzenlemiş olduğu online derste (29.07.2015) katılımcıların yazılı sorularına verilen cevaplar aşağıda yer almaktadır. Dersle ilgili daha fazla bilgi için tıklayınız.
Chairperson: The recording and slides from the first class are located here https://developer.nvidia.com/deep-learning-courses
Jonathan Bentz: N Frick: I have a question: are any of the recent algorithm advances already “baked” into the DL Frameworks, or is it up to the user to choose the correct preprocessing methods and implement them outside the libraries?
A: Depends what you mean by “algorithm advances”. In general, the DL frameworks make every attempt to keep up with the current state of the art in deep learning algorithms and so they often implement these directly in the frameworks.
Brent Oster: Sunny Panchal: Once a network has been trained, how well does it adapt to a new set of data that is added with a new classification category?
Yes, this is referred to as fine tuning, and it works because many of the lower-level features are common between datasets. Only the weights for the fully-connected layers need to be adjusted.
Allison Gray: Earl Vickers Question: Can DIGITS handle arbitrary data types without a lot of programming, or is it mainly designed for pictures?
A: Right now you can use square or rectangular images with DIGITS. They can be either color or grayscale. We can also handle different image formats. We plan to expand this in the future.
Earl Vickers Question: Can DIGITS handle arbitrary data types without a lot of programming, or is it mainly designed for pictures?
A: Right now you can use square or rectangular images with DIGITS. They can be either color or grayscale. We can also handle different image formats. We plan to expand this in the future.
Earl Vickers Question: Can DIGITS handle arbitrary data types without a lot of programming, or is it mainly designed for pictures?
A: Right now you can use square or rectangular images with DIGITS. They can be either color or grayscale. We can also handle different image formats. We plan to expand this in the future.
Larry Brown: There are a few questions about invariance in DNNs and including metadata…those questions are more advanced and we will come back to them in a future session.
Brent Oster: Q: Ferhat Kurt: Is it possible to image recognition realtime in a stream (video)?
A: Yes, image recognition in a video can be done by applying a convolutional neural network to the decoded frames. If additional information about what is happening in the video is desired, a recurrent neural network can be added below the CNN to capture temporal features in the video
Allison Gray: Kartik Hegde: My question is : I am planning to get an image recognition system on an embedded system, where I want a real time object recognition. Do you think CNN’s suit for realtime on embedded processors, say Tegra K1?
A: I have been able to classify images with trained networks by Caffe on the Jetson. Classification times can vary depending on how you are classifying your images. We have seen up more than 30 images per second.
Allison Gray: Q-david perticone: If I have built a model with digits, how would I get a list of classifications on a large >50k new set of images?
A: You could use the Classify Many feature to show you at a glance how well your network is able to classify the new/unseen images. Personally, I would download my trained network files and then use a python script to classify and log the classification results.
Brent Oster: Q: Jae Lim: Is DNN same as recurrent neural learning?
A: Recurrent neural networks are a type of deep neural network where connections can feed back into the network, allowing cyclical loops in the network. These are good for learning temporal features
Allison Gray: david perticone: There seem to be very strict limits on the size of the images (never seem more than 256×256). Do all the images have to be the same size and what id the big “O” of the image size
A: Yes, the images need to be the same size before being ingested by Caffe. However you can change your dimensions to a larger size like 512×512 or even rectangular such as 200×400.
Brent Oster: Q: Sunny Panchal: Also, Would a deep learning network be able to pick up patterns over different time periods? Would a variable from the past be able to influence the present outcome?
A: This is a good use case for a recurrent neural network, which can discern temporal and contextual information from the data
Allison Gray: Bálint Tóth: how can one decide which DL framework to use? (Caffee, Torch, Theano, etc.)
A: Great question. I personally think all of the frameworks are good. They all have great documentation and examples to help one get started
Larry Brown: Neeharika Adabala: Is there a particular network architecture suitable for NLP, unsupervised clustering of text data?
A: For NLP, people generally use a class of deep neural network called Recurrent Neural Networks (RNN). A great intro tutorial on RNN for NLP can be found here: http://nlp.stanford.edu/courses/NAACL2013/
Brent Oster: Q: Fallak Asad: Actually i wanted natural language processing in images, such as identifying names, organization, address so what is the most useful architecture i could use,simple neural nets, RNN or convolutional NN?
A: I would use an LSTM RNN with a CNN on top. The CNN processes the image to pick up the salient features, and the RNN can decode the sequences of letters/numbers
Larry Brown: Piyush Singh: Is a big DLNN always better performing than a smaller one?
A: That depends, actually. Remember that for DNNs you need a lot of data to avoid overfitting. If you are not able to provide more data to your larger DNN model, then it may overfit (ie. simply “memorize” all the examples)…and thus perform poorly on new real-world examples. That said, if you have lots of data, then yes, larger models generally do better.
Jonathan Bentz: juan david aguilar: is there a book of deep learning with exercises???
A: There are likely many books, but if you want exercises I recommend trying Andrew Ng’s course on machine learning found on Coursera. The deep learning frameworks like Caffe, Torch or Theano also have lots of documentation including tutorials and exercises.
Larry Brown: alireza aliamiri: is NN suitable for sequences such as language?
A: Yes, absolutely. DNNs are having a lot of success in speech and text processing. We use a particular type of DNN called an RNN – Recurrent Neural Networks (RNN). A great intro tutorial on RNN for NLP can be found here: http://nlp.stanford.edu/courses/NAACL2013/
Brent Oster: Q: Srivatsa Bhargava J: Do we resize the images before presenting it to the input layer of the DNN (Construct a image pyramid) as in techniques like DPM ?
A: Yes, usually images are resized to a common resolution before being input to a DNN. They can also be normalized.
Allison Gray: Hamid Eghbal-zadeh: I have downloaded DIGITS, but since it depends on cuda, I can not use it. I couldn’t install cuda because I don’t have a graphic card that supports cuda. Is there any way to use digits without a gpu, only using cpu?
A: You can. DIGITS works with Caffe on the backend. So you need to rebuild Caffe without CUDA. Go into your MakeFile.config file and uncomment CPU_ONLY:=1.
Brent Oster: Q: saikiran bonthu: What if i have limited data and i want to avoid overfitting with DNN. How to fine tune DNN in that case.
A: You can regularize the weights by penalizing large values in the cost function
Larry Brown: Andre Cunha: Could you please leave some comments about how deep learning relates to SVM?
A: SVM = Support Vector Machine The SVM is not a neural network technique, it is a “traditional” statistical machine learning technique. It remains one of the most popular machine techniques today. Some people would say that it is more difficult to scale an SVM classifier to a really large dataset — that DNNs scale better.
Mark Ebersole: Vladimir, RNNs will not be covered in the first 5 classes in this course, but we’re looking to add them in more advanced follow up classes. Stay tuned!
Allison Gray: Mitja Placer: In a multi GPU configuration, does Digits need the GPUs to be of an exact same model or can they be different, eg. a Titan X and a GTX 780?
A: You can have different GPUs. But you may have to reduce your batch size to account for memory on the smaller GPU. If you have 3 or 4 GPUs, say 2 Titan X and 2 GTX 780, you can select which GPUs you would like to use for each training.
Brent Oster: Q: Subramaniam Kalambur: is it possible to use deep learning to recognize a particular action within video, like waving a hand?
A: Yes, this is commonly done with a combination of a 3D CNN to extract spatio-temporal features and an RNN to recognize sequences of those features
Jonathan Bentz: Jiangbo Yuan: Hello. Can you please talk about the advantage by using batch processing? I am using Caffe, and it seems the batch processing has no benefits with CPUs. Any insights from DIGITS about batch processing?
A: Batch processing is very popular on GPUs because you can tune the batch size to correspond with the amount of memory (RAM) on the GPU. When the batch size fits into GPU memory the training computations are quite efficient on GPUs.
Larry Brown: Sapan Mankad: Which DL framework and architecture is the most suitable for working with speech signals?
A: The most popular toolkit for speech and text processing is probably Kaldi: http://kaldi.sourceforge.net/about.html
However, certainly Torch and Theano are popular for speech as well. With regards to architecture, the RNN (Recurrent Neural Network) is the main one.
Brent Oster: Q: Andreas Doumanoglou: can deep learning be used for online training, using very few images e.g. from a mobile phone ?
A: Commonly you need hundreds of thousands, or even millions of images to train a convolutional neural network properly. With only a few images you run the risk of overfitting
Allison Gray: Piyush Singh: Does the ordering of the training data matter?
A: With some of my tests, shuffling helped me train more effectively. Without shuffling for my small datasets I found an oscillation in my training results.
Jonathan Bentz: Deven Patel: How suitable is OpenCV for Deep learning?
A: OpenCV is used very often when doing computer vision tasks. It is quite popular.
Larry Brown: Ara Danielyan: How do you come up with a configuration of neural network for a particular task? In other words, why do you set up a convolution layer followed by a pooling layer following by a Local Response Normalization layer etc for image recognition? Are there any principles in selecting the order of layers, or this is a black magick process?
A: Great question. We will speak to this later in the course. At a high level, building a neural network architecture requires a solid understanding of machine learning techniques. The details of the core network architecture are driven by a combination of mathematics, the experience of ML researchers (trial and error) and ideas taken from related areas (such as neurophysiology – how does a “real” neural network do it). If you are new to DNNs, then you definitely want to start with one of the well known existing architectures, and then make tweaks from that starting point as you get experience.
Mark Ebersole: Jon meant “a positive real number less than one” 
Jonathan Bentz: Tharindu Mathew: is there a benchmark for commodity GPUs for say a common dataset, for training and testing?
A: There are published results for some of the public deep learning frameworks. There is also the ImageNet competition which is open to the public. I’m not aware of a pre-canned benchmark that is ubiquitous as e.g., High Performance Linpack (HPL) is for HPC systems.
Larry Brown: Jack Ketola: Would it be better to use a Titan X instead of a gtx 980 ti?
A: A Titan X GPU is indeed a more powerful GPU than a GTX 980 TI. Both are excellent choices for starting out with deep neural networks. The Titan X has a bit more compute capability, because it has a few more SMs (streaming multiprocessors) than a 980. The most important difference between the two GPUs is that the Titan X has twice the memory, 12GB versus 6 GB. You can fit larger models on the TItan X. Both are excellent.
Allison Gray:
Ara Danielyan: Not sure if you missed my question… How do you come up with a configuration of neural network for a particular task? In other words, why do you set up a convolution layer followed by a pooling layer following by a Local Response Normalization layer etc for image recognition? Are there any principles in selecting the order of layers, or there is no such methodology?
A: Interesting question. There is a lot of activity around developing the right DNN for your data. AlexNet the winner of the ImageNet 2012 Competition has 5 convolutional layers and two fully connected one. Then the GoogleNet network which won in 2014 is have even more layers and proved to be more accurate.
One reason to pool the data is to reduce dimensionality while still showing filters response with respect to that portion of the input image.
Couple things to remember about convolutional layers, if you don’t zero pad your input image is reduced by the radius of the input. This combined with pooling reduces the input data.
Brent Oster: Q: Philip Chen: can a typical deep learning application be run on a modern PC? what computing resources are typically needed?
A: Yes, a desktop system with a TitanX GPU can effectively train large neural networks in a reasonable amount of time
Allison Gray:
Earl Vickers: Are there any easy-to-use frameworks that would be suitable for audio or arbitrary data types?
A: You may want to look at Kaldi – http://kaldi.sourceforge.net/index.html for audio. Torch also has a audio module that you might want to look at https://github.com/torch/torch7/wiki/Cheatsheet#audio
Larry Brown: Seyedmajid Azimi: Can I use CNNs for Image registration problem which uses two images from two different sources and produce a combined image?
A: Certainly the answer is “yes”. I don’t have a reference handy to provide you. This is a more advanced topic so I will note it and hopefully we can address this in a later session.
Jonathan Bentz: John McInerney: Can the models be deployed with a reasonable run time on a machine that does not have a GPU; that is, CPU(s) only?
A: One can always do both training and classification both with and without GPUs. For training especially GPUs are becoming the defacto standard in many cases. For classification people do use GPUs and they also use CPU-only systems. Classification is much less computationally-intensive so CPU-only systems there seem to be quite popular.
Jonathan Bentz: Philip Chen: can a typical deep learning application be run on a modern PC? what computing resources are typically needed?
A: This really depends what you mean by “typical”. It is certainly the case that a modern PC with GPU has the capability to train quite large networks. For example, while not a typical PC, the DIGITS devbox (https://developer.nvidia.com/devbox) has the ability to handle a great deal of popular deep learning training tasks.
Allison Gray: Olivier Philip: What technique do you recommend to counter overfitting and when ?
A: Monitor your accuracy with the test data and loss. I have found that over time, my accuracy with the training data will continue to improve and at some point over fitting. The accuracy with the test data reaches a minimum and this is the point where my trained NN is most effective, WRT my test data (data it has not seen and is not used for training).
Allison Gray: Piyush Singh: Is the AWS cloud a suitable platform for training DLNNs? Or is it better to source my own GPU?
A:I use AWS for a lot of my DL tinkering. It gets the job done. However, my training times are greatly reduced when I use other GPUs, such as K40 and Titan X.
Brent Oster: Q: Tharindu Mathew: Are DNNs fast enough in classification tasks for commercial applications (Siri/ Google Voice Search), or are they used in conjunction with some classical ML techniques?
A: While we can’t divulge specifics of what companies are using, I think it is safe to assume that DNNs can be used in real-time speech recognition and natural language processing
Larry Brown: Deep Chakraborty: I have heard that sometimes the output of a CNN is fed into a SVM. Why is this necessary? Isn’t CNN adequate for classification purposes? Is CNN used only for feature extraction?
A: In general people use DNN/CNN for the entire pipeline, not just feature extraction. However, SVM is a very powerful technique. By using DNN lower layers you get to harness the ability of the DNN to scale to large inputs and datasets. Putting an SVM on top then gives you a strong statistical technique to feed those features into. SVMs are probably more well understood, by more people, from a mathematical perspective than DNNs. I’ll note this question as “advanced” and we get a further answer for you in a later session.
Mark Ebersole: Sapan, even in our first hands-on lab there were demos other than image processing (i.e., text). We will attempt to demonstrate a wide variety of domains!
Allison Gray:
Ambar Pal: What are the common reasons behind a network not training properly(for example the loss staying constant and the accuracy not improving)?
A: I have found that when my network is not training, I often need to reduce my learning rate. For Caffe, I look at my loss value and check to see if it is increasing. If so, I first try to reduce my learning rate.
Jonathan Bentz: Melanie Warrick: Is CUDA based on OpenCV?
A: No, CUDA is NOT based on OpenCV. They are separate but there is a portion of OpenCV that is written using CUDA to provide for efficient performance on NVIDIA GPUs.
Brent Oster: Q: Mohammad Ali Bagheri: Could you please introduce an easy-to-use CNN for image/video classification?
A: NVIDIA Digits on top of Caffe is a great place to start for image classification, and Caffe with 3D convolutions would work for video.
Mark Ebersole: Q: Can we use the online cuda cluster given in the handson labs for our own experimentation A: You can use the AWS environment for experimenation, but the hands-on labs are time-limited and are not a great avenue for experimentation.
Larry Brown: gianfranco campana: I’m planning to analyze in real time the directions the consumers eyes are watching. Are the size of pupils enough large to be intercepted in images visualizing half to full body? What it the lower size limit a portion of images has to be, to be meaningful?
A: This sounds like an empirical question. For very accurate eye-tracking people usually use cameras that are mounted right in front of the face. I’m sure it will come down to the resolution of your images, and what level of direction accuracy you need. Sounds like a great project though — good luck