Human actions capture a wide variety of interactions between people and objects. As a result, the set of possible actions is extremely large and it is difficult to obtain sufficient training examples for all actions. However, we could compensate for this sparsity in supervision by leveraging the rich semantic relationship between different actions. A single action is often composed of other smaller actions and is exclusive of certain others. We need a method which can reason about such relationships and extrapolate unobserved actions from known actions. Hence, we propose a novel neural network framework which jointly extracts the relationship between actions and uses them for training better action retrieval models. Our model incorporates linguistic, visual and logical consistency based cues to effectively identify these relationships. We train and test
our model on a largescale image dataset of human actions. We show a significant improvement in mean AP compared to different baseline methods including the HEX-graph approach from Deng et al.
Etiket: Li Fei-Fei

Makale: ImageNet Large Scale Visual Recognition Challenge
Everything you wanted to know about ILSVRC: data collection, results, trends over the years, current computer vision accuracy, even a stab at computer vision vs. human vision accuracy — all here!

Makale: Deep Fragment Embeddings for Bidirectional Image-Sentence Mapping
We train a multi-modal embedding to associate fragments of images (objects) and sentences (noun and verb phrases) with a structured, max-margin objective. Our model enables efficient and interpretible retrieval of images from sentence descriptions (and vice versa).

Makale: Large-Scale Video Classification with Convolutional Neural Networks
We introduce Sports-1M: a dataset of 1.1 million YouTube videos with 487 classes of Sport. This dataset allowed us to train large Convolutional Neural Networks that learn spatio-temporal features from video rather than single, static images.
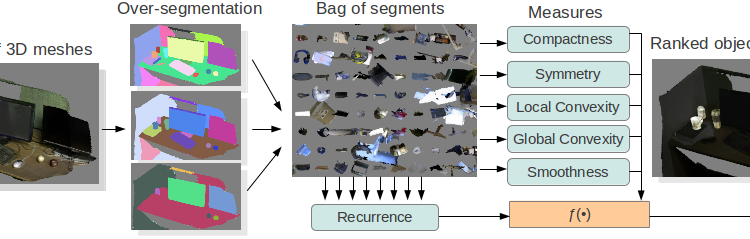
Makale: Object Discovery in 3D scenes via Shape Analysis
We present a method for discovering object models from 3D meshes of indoor environments. Our algorithm first decomposes the scene into a set of candidate mesh segments and then ranks each segment according to its “objectness” — a quality that distinguishes objects from clutter. To do so, we propose five intrinsic shape measures: compactness, symmetry, smoothness, and local and global convexity. We additionally propose a recurrence measure, codifying the intuition that frequently occurring geometries are more likely to correspond to complete objects. We evaluate our method in both supervised and unsupervised regimes on a dataset of 58 indoor scenes collected using an Open Source implementation of Kinect Fusion. We show that our approach can reliably and efficiently distinguish objects from clutter, with Average Precision score of .92. We make our dataset available to the public.